Modern AI implementations work, kind of well. No matter if you are following all of the latest trends and doing things the 'right' way — maxing out your tokens on Claude Code, using a custom knowledge base like an LLM Wiki or Obsidian, or running OpenClaw on a warehouse full of Mac Minis — you still probably have felt a twinge of confusion that things aren't working just like they should. Whether:
- Your agents aren't aware of the right context. They constantly need to be reminded of things they already know.
- Your OpenClaw bill amounts to thousands of dollars in bills a month.
- Your knowledge base holds data, but all your tools or corporate APIs need to be installed, provisioned, and monitored manually.
You are left with the pain points and headache of coordinating and integrating these systems. You are not alone. The entire industry is stuck here, now. Let me explain why.
The Memoryless Nature of LLMs#
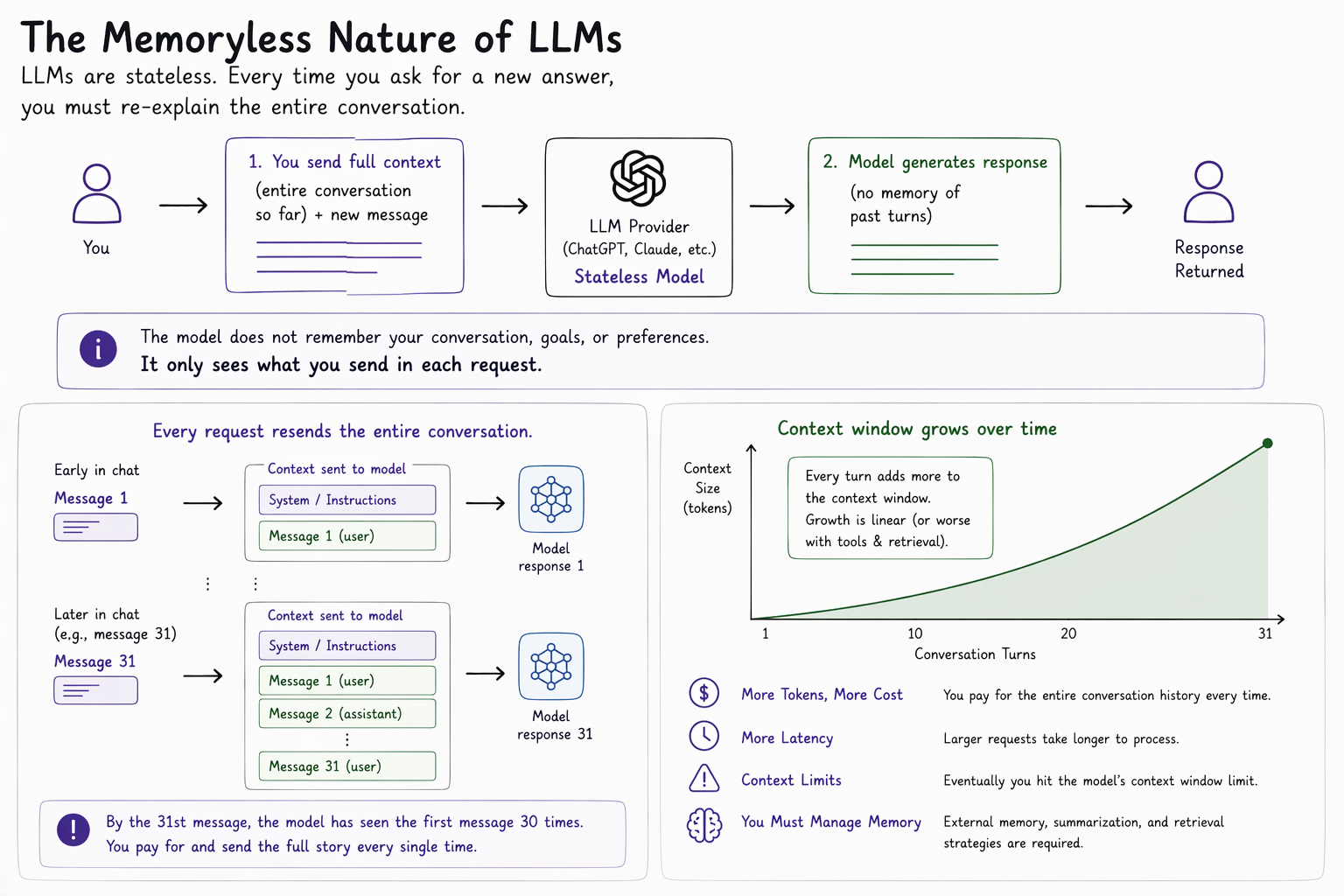
The way that modern LLMs work is that they are stateless. This means that when you interact with ChatGPT or Claude through any program — one you write yourself or use — every time that you want a new answer from a model you have to re-explain the entire problem.
This is because LLMs have no memory. They are trained once, and then refined globally by frontier model providers. Each time a program sends a message to a model provider, it needs to also send the full story of the conversation prior to that last message. By the time you send your AI the 31st message in a chat window, it has seen the first message thirty times.
From Chatting to Web Browsing#
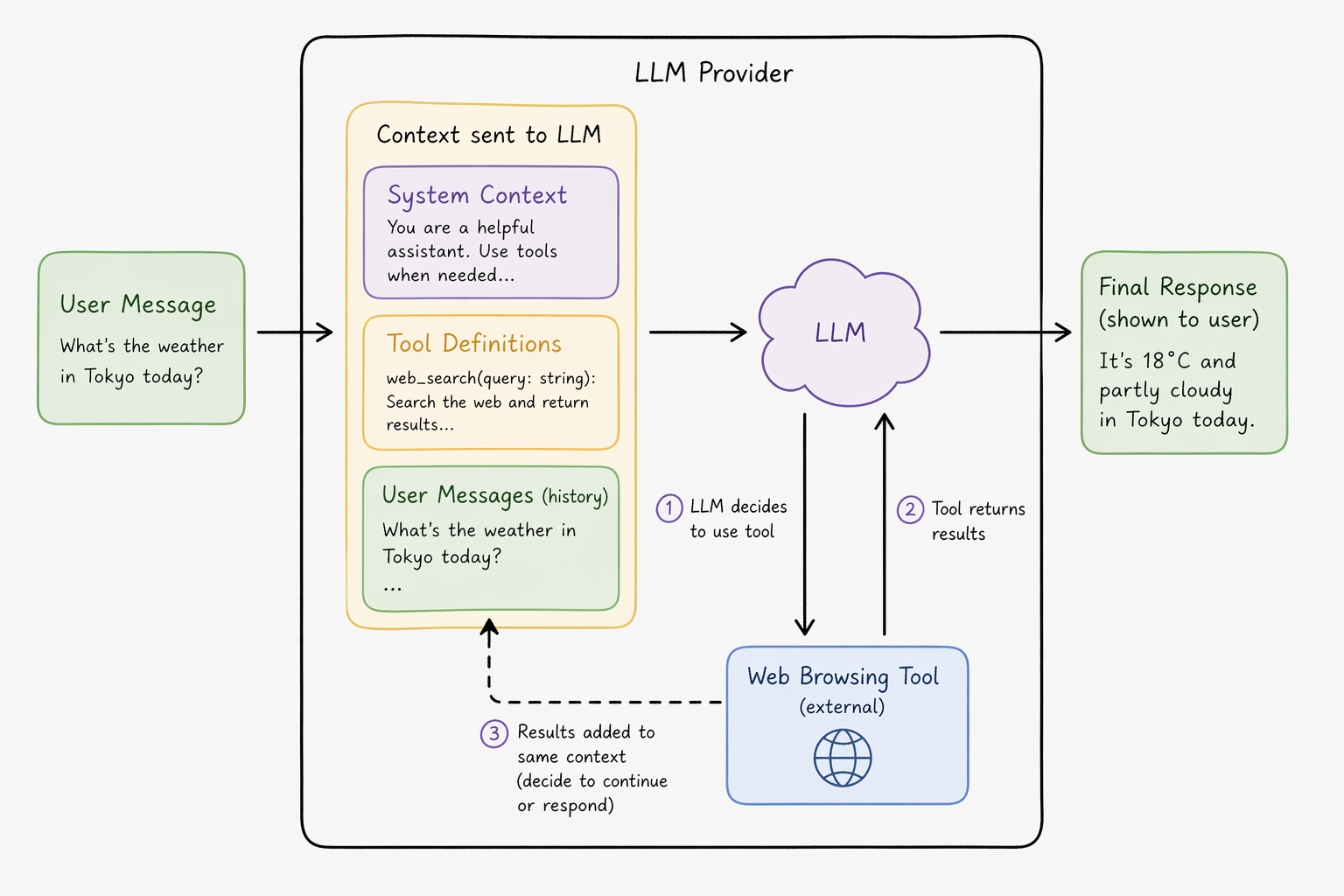
The initial pattern of use for LLM-based applications involved LLMs providing text output shown directly to the user. Shortly thereafter, model providers started including web browsing capabilities with their chat applications. These were the agentic implementations of LLMs.
The model providers took user messages and sent them to their LLMs in prompts which included additional sets of options called tool calls. These gave their LLMs the option to get some information, and add it back to the same context the LLM received from the user instead of responding to the user directly. This resulted in behaviour that made it appear as if their models had a form of continuous memory, as they could decide to do more research or finally respond. In reality, they were implementing the first kinds of control systems that make the LLMs appear like continuous agents, when in reality, the system as a whole was doing the work of maintaining a continuous thread of memory.
From Web Browsing to Browsing Your Computer#
These systems of input, decision, and feedback turned out to be extremely effective, and the structure became the default pattern for most custom agent solutions.
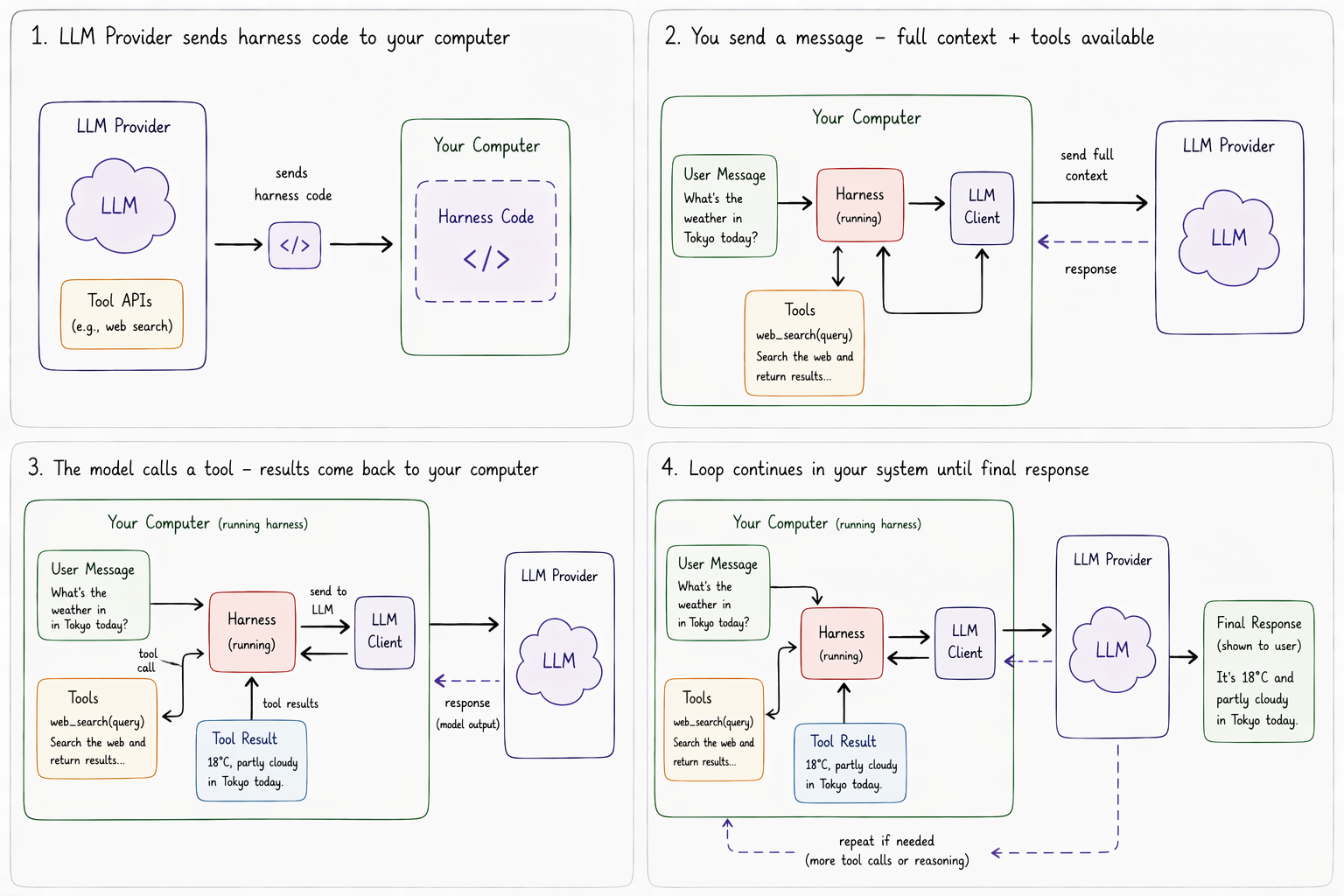
It then became clear that instead of isolating the decisions of what an LLM could learn more about to the web, the observation was made that by providing the tools to make a user's system inter-actable like the web, one could allow for iterative, informed LLM execution in the same way.
Claude Code was the first implementation of this that enabled near-human-level task completion capabilities. The system was not differentiated by its LLM's capability, but by the right combination of classic rule-based code that transformed the user's local computer into sets of actionable tools their LLM could interact with. This code that managed the entire life cycle — including tools, file system accessibility, memory management, and user file updates — became broadly understood in the industry as a harness.
Harnesses manage the evolving story — ruling out what gets shown to the LLM every turn it runs in a 'self selected' agentic workflow:
- What information on your computer gets tucked away behind 'buttons' that the LLM can choose to press to 'see more' in the case it may be relevant for the LLM to respond to the user.
- The actions the LLM can decide to run to modify your computer and how it can see the results.
- The external information sources the LLM can suggest the harness subscribe to, so that it can be notified if anything relevant to the goal changes.
Eventually, the entire prompt shown to LLMs became a description of harness tools and how to call them for the user-provided goal of a given agentic workflow (a set of LLM prompts which collectively form a continuous narrative to achieve a single user-facing goal).
The LLM Interfacing Problem#
There are two ways to read the user-facing failures we opened with — the litany of reasons modern LLM stacks work only kind-of-well.
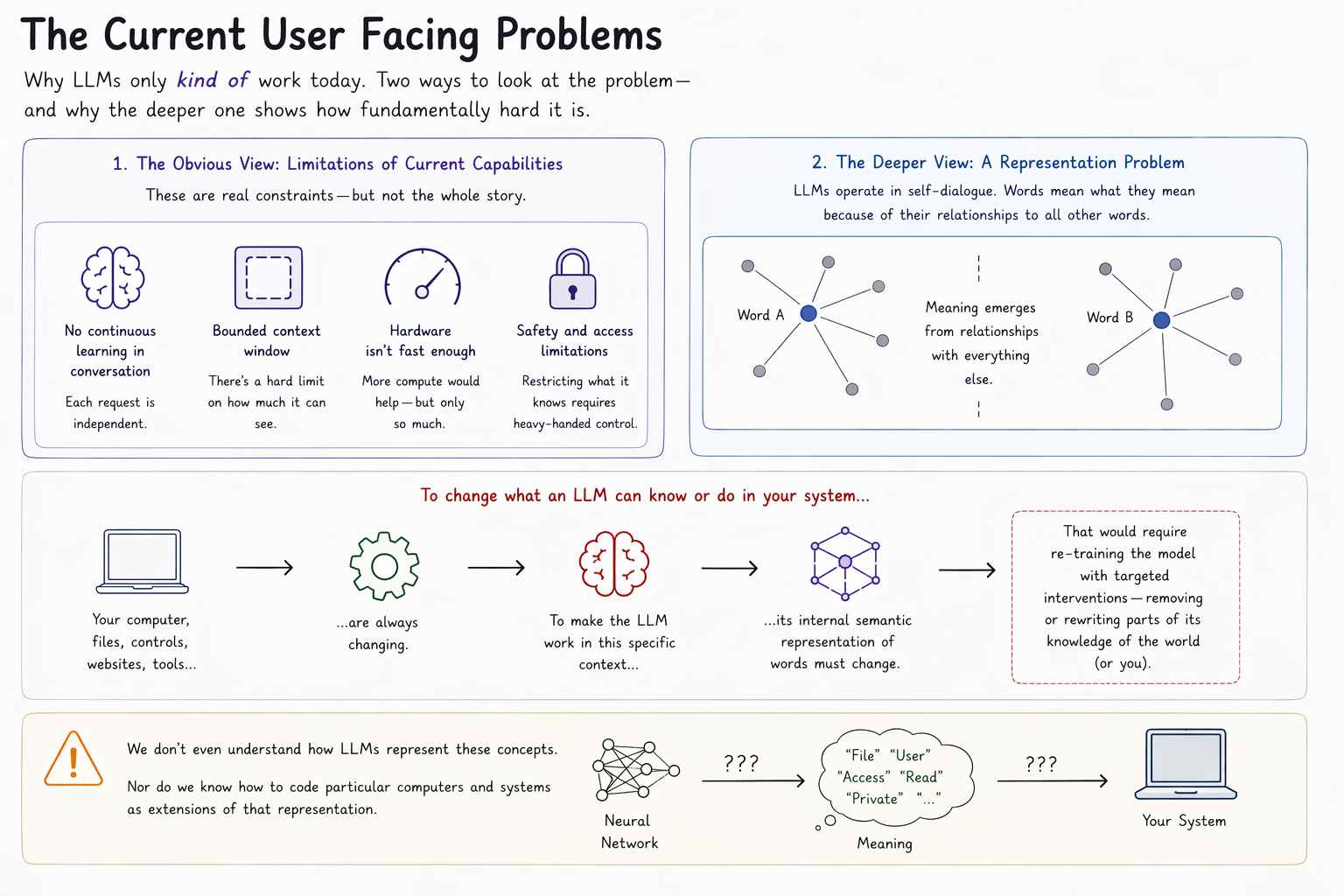
The first reading is that these are capability problems. The model can't learn continuously from an ongoing conversation. Context windows have a ceiling. The chips aren't fast enough. Wait for the next generation, and the friction will lift.
That reading runs into a deeper problem. An LLM is a self-referential semantic web — every word's meaning is constituted by its relationships to every other word. To get a model to behave differently in a specific context, you would need to alter those relationships. Specifically. For your context.
Consider what that would actually demand. The tools, files, permissions, and integrations that govern how an LLM interacts with your system are continuously changing — and changing in ways whose whole point is to control what the model can do and know. To represent that shifting structure inside the model would mean encoding your computer, its access controls, and every website and document it engages with, in the same representational language the LLM uses internally. Restricting file access would no longer be a config change; it would amount to a targeted re-training that surgically removes a slice of the model's neural network.
But we don't understand how LLMs represent the concepts they appear to use. Nor do we know how to encode arbitrary computer systems as LLM-native extensions.
A Problem in Harness Design#
Any effort we take to solve current LLM usability problems as they stand is much more likely solvable in short order by addressing how we build harnesses, and how those harnesses load data from the world into prompts an LLM can interact with. Then we look at the problems from the beginning:
- The runaway costs on OpenClaw? A problem with giving a harness the right tools to know when to re-run a particular agentic workflow without needing to use an LLM every 8 seconds and incurring runaway heartbeat cost.
- The manual tool procurement processes for an organization? Current harnesses aren't designed to enable the LLM to install its own tools and use them correctly, or safely.
- The agent reminder problem? Harnesses aren't summarizing old messages in ways that appropriately capture the most meaningful considerations each LLM interaction turn.
All of these problems are driven to extremes when we use agents for the corporate use case, where:
- Data exists on the cloud with complex and nuanced permission systems.
- Agents need to run on the cloud cheaply, to do continuous meaningful work, but they also need to be created and destroyed much faster than one can access, set up, and tear down execution environments they can run within.
- The amount of information that should be explorable to agents is hundreds of thousands to millions of documents.
The harnesses of the future need to be able to solve these problems, and one more: they need to be able to replicate. The reason is simple. At least one harness needs to exist for each 'task' a user gives to an LLM. But that LLM can choose to spin up a 'sub-agent' to run when it breaks that task out to many other tasks. These sub-agents may want to run their programs, store their own data, and execute isolated experiments. That requires more harness capabilities, which may need to run on new computers.
These means we may need to create more harnesses, and the fundamental solution isn't the harness itself, but in managing how everything works, together, across all the computers running your cloud.
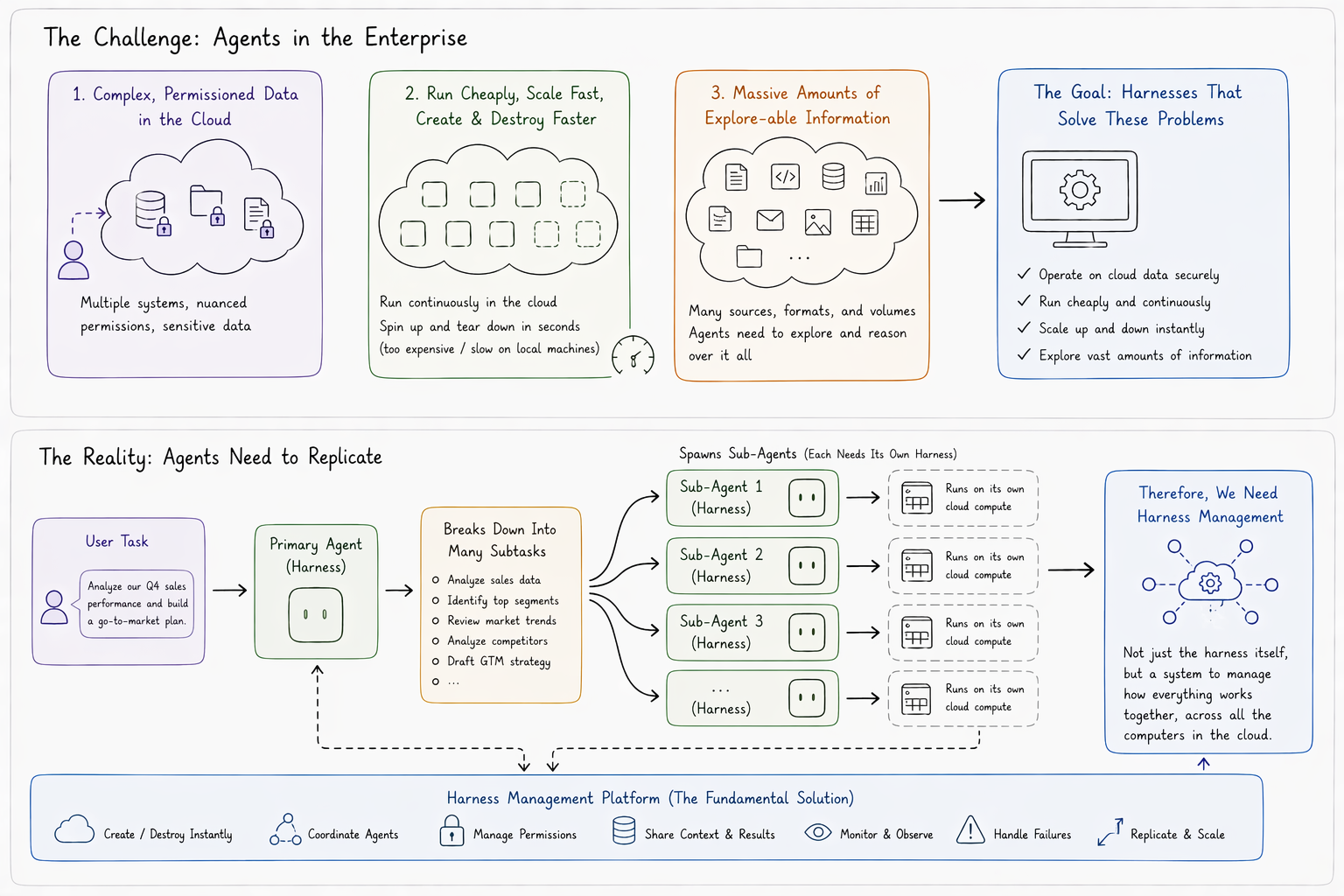
The Many Agent, Many System Problem#
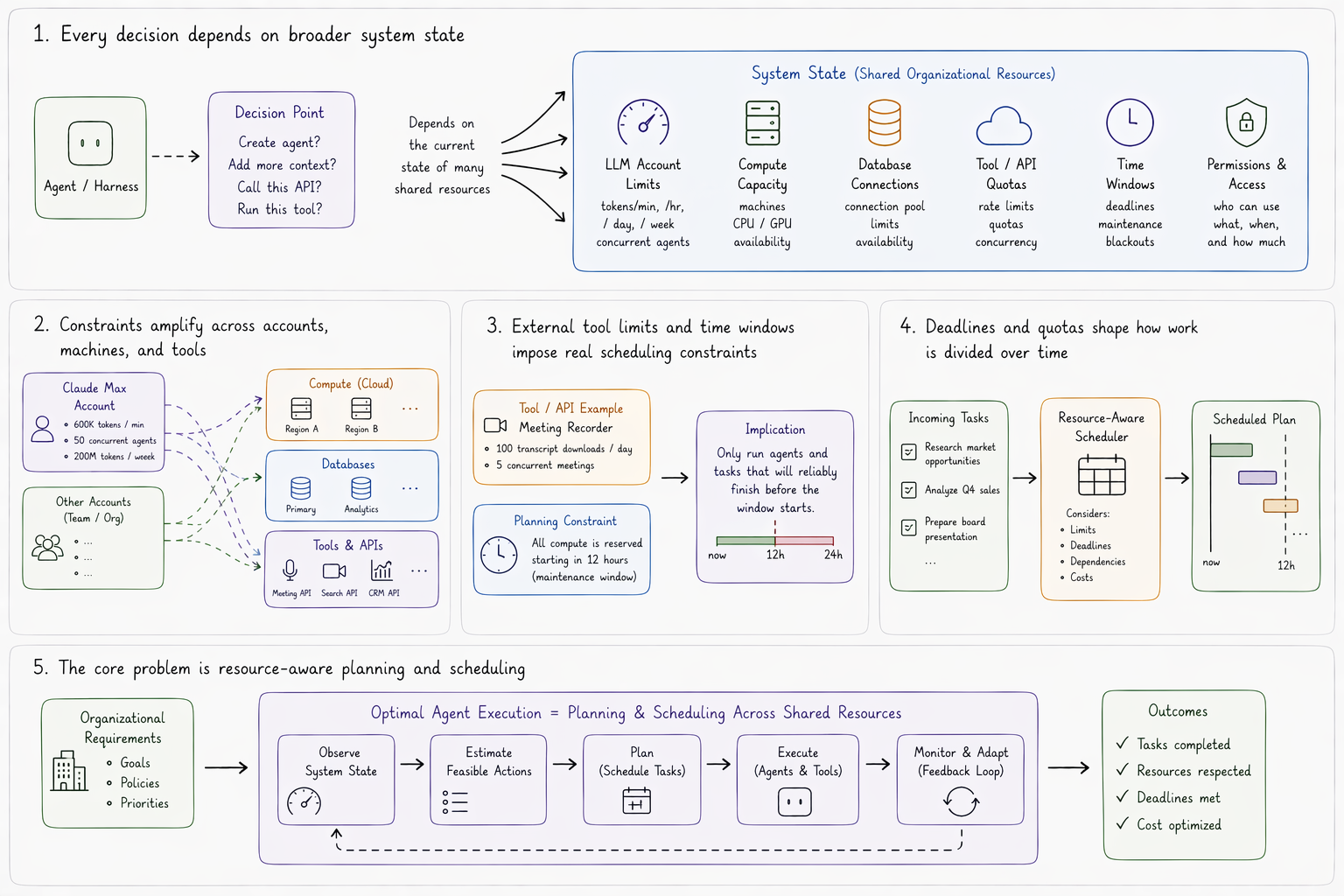
Whether or not you can even offer an agent the capacity to run a particular tool, or to qualify the wisdom of calling an API, is always dependent on broader system state.
If you have a Claude Max account, you get a certain amount of agents and tokens per minute, second, hour, and week. That account becomes a critical resource in determining whether or not you should or can create an agent, add more context to your LLM call, or run an intermediate step in your harness. If you need to run agents on multiple machines on the cloud, the co-ordination constraints amplify. Not only do your tokens become a critical resource, but your machine and database connections as well.
This extends to commercial tool use for data critical to teams and organizations. If your meeting recorder account only allows a certain number of transcript downloads, or concurrent meetings, those considerations become important for dividing up access for different use cases over time. If you plan to use all your machines starting twelve hours from now, then you can only allocate agents to new tasks which will reliably finish before then. These kinds of requirements impose deadlines on agents themselves.
So long as context windows exist, the entire problem of running optimal agents for organization requirements reduces to a planning and scheduling problem across a shared organizational resource plan.
Planning, Scheduling and Control#
Planning and scheduling problems are well known in most optimized business domains, and they follow a similar pattern:
You have some limited number of resources which you can use to accomplish a task, and how you use them can affect future resources availability. You plan to control some symbolic state of the system which maps to your real-world objective — like, for example, the number in a budgeting Excel which represents vacation savings.
You take in data about how much you usually regularly spend, and forecast that into the future. You account for things you need to buy in order to survive and may make trade-offs. The end result is a resource allocation plan. These plans tell us the best actions we can make in order to achieve our goal — like how much less you need to eat out, in order to go on your desired vacation.
If when running your budget you realize that the plan says the best way to have money for your vacation is to pay off your credit card debt right now, then you should do it, right now. If by contrast the plan says to pay the bill in 14 days before its due, because you might need spare cash until then, you wait 14 days (and re-visit your budget in the meanwhile) before allocating resources.
This is the basis of control systems. The most advanced applications are model predictive control and hierarchical reinforcement learning applications of AI. Many industry leaders are pursuing these types of systems in lieu of general transformers — they exist in very different branches of computer science than LLMs, and do not integrate with them cleanly.
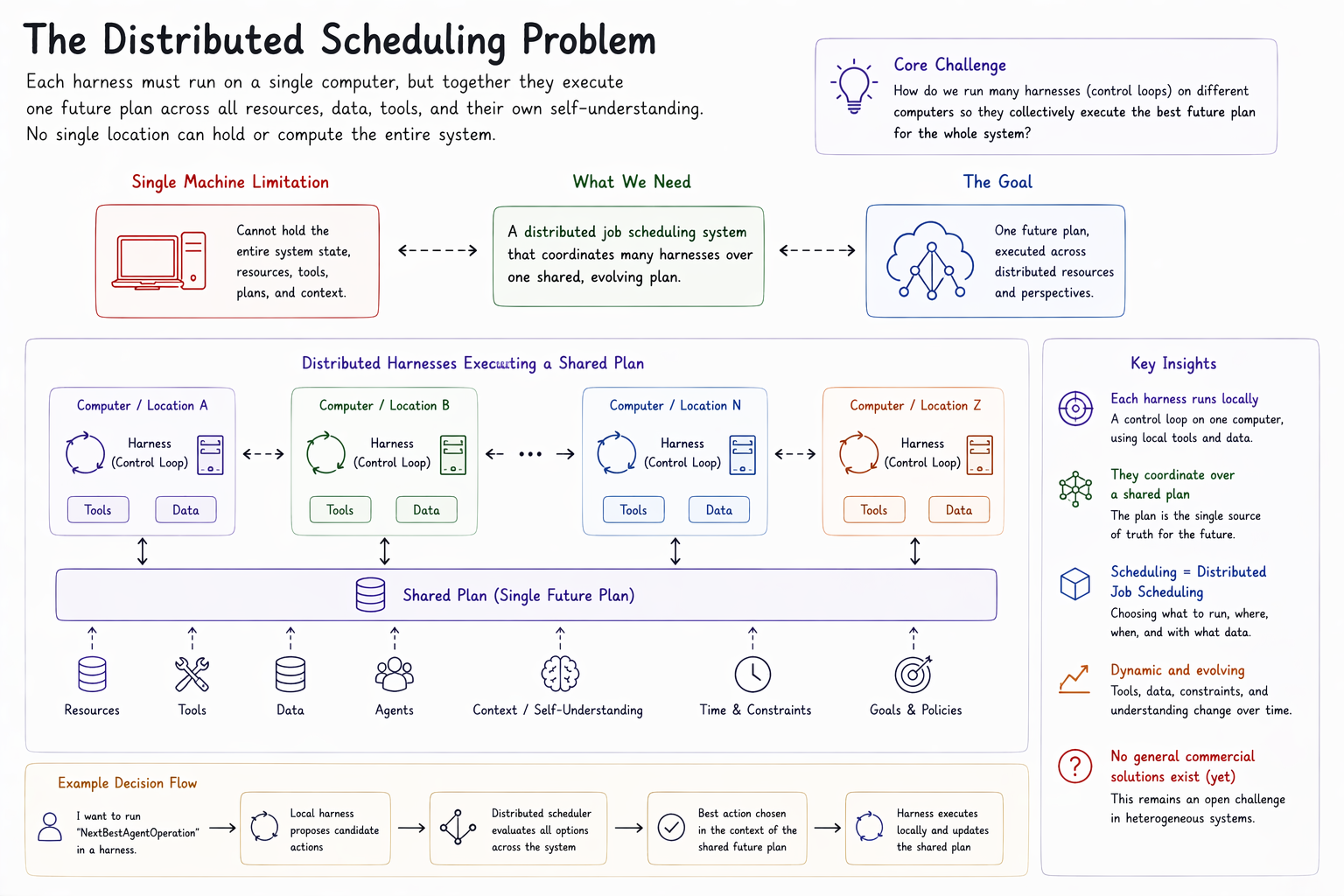
The Distributed Scheduling Problem#
So, we want to use a control system loop run each harness, but we have a problem. Unlike the luxuries of the past, where logistical control systems were built over hard-coded business concepts, structure, and rules — our system considerations evolve with our tools, which we want to make dynamic, flexible, and evolving alongside the data on our business clouds.
Beyond that, each harness needs to run on a single computer, but the entire system represents a single future plan across its own resources — which include its own self-understanding. So, each location where we do planning and scheduling can't hold the entirety of the system we are planning and scheduling for.
The problem of running harnesses reduces to a distributed job scheduling problem over a shared plan, which includes planning time to perform that distributed job scheduling problem over a shared plan. If I want to run a NextBestAgentOperation tool within a harness, I am implicitly answering my own question. That tool, apparently, was already the best. But it may not be.
This has long been the challenge in high-performance computing, but only now has it sufficiently generalized to become truly heterogeneous in warranted considerations. And there are no general commercial solutions for it as of yet.
Language: The Universal Coordinator#
We have gone over how the problem of managing harnesses with agents — and how the agent management problem reduces to a distributed task planning and scheduling problem, where the tasks are executions of the system's own functions.
We solve this by recognizing that the solution to our problem cannot be the design of any standalone component, but instead must be defined as the interaction boundary across them.
So, we extend the language of our tools to define, or describe, their impact on the collective future, and we use refinement of the harness's language itself to bridge the gap between the collective plan of network nodes and something which represents our cumulative future expectation.
By building a unifying language where tools and environments, and adherence to their established definitions, define terms, we can formulate a basis to co-ordinate across shared resources, tools, and a plan.
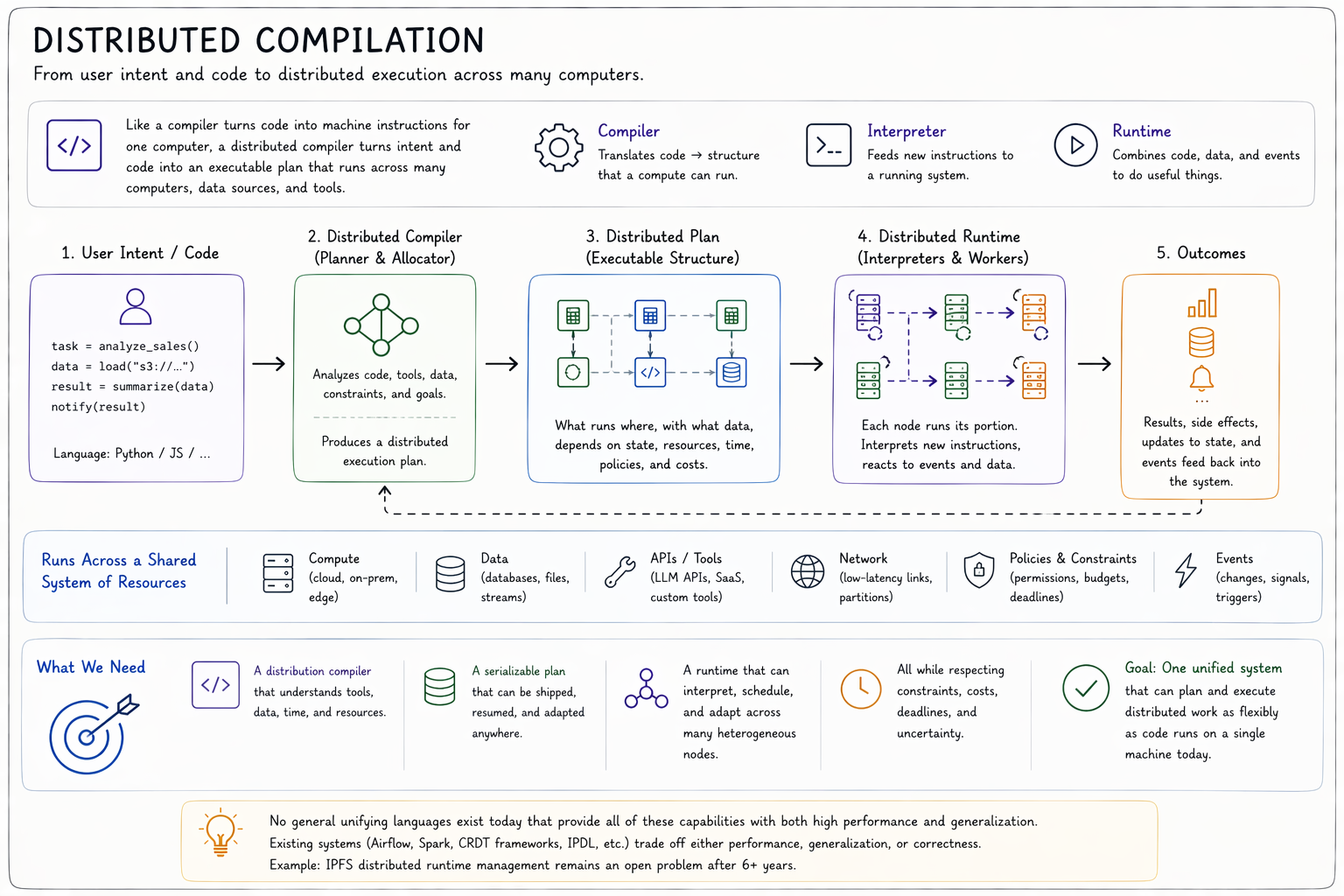
Distributed Compilation#
Computer languages are processed by something called a compiler. The compiler takes user code and translates it into structure that a computer can actually run, or compute things with. An interpreter is a program in the system that takes new lines of code and feeds them to an already-running program.
A runtime combines these facilities with system data and events to actually do useful things. Most computer languages are written to run in one-platform runtimes. Their functions and features are not built to be distributed across computers.
When we define a list of data in common languages like JavaScript or Python, the data is expected to be contained within a single computer or program. All system components that take the user code and divide it to actual machine hardware are done underneath. We require the same faculties as instruction-to-machine co-ordination in conventional languages but need this allocation across our computers.
No general unifying languages exist that meet the requirements of our distributed scheduler/planner model. Existing solution attempts (Apache Airflow, Spark, CRDT frameworks, IPDL) either sacrifice performance or generalization. If they didn't, the distributed harness problem wouldn't exist at scale, no-one would pay for Kubernetes, the advanced data layout problem wouldn't be a six-year open question for IPFS, and CRDT frameworks would exist at the compiler — not the application customization layer. But, they don't.
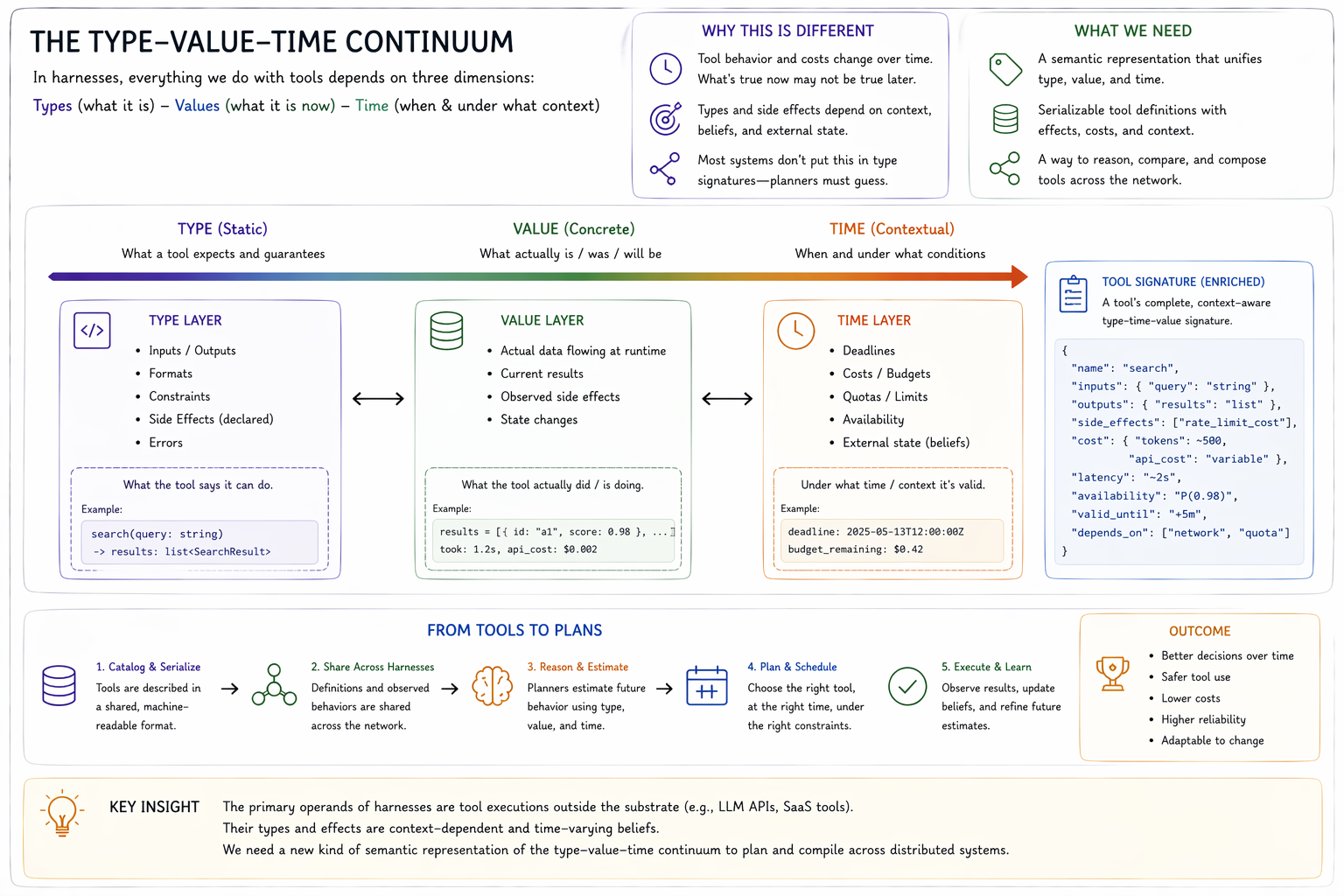
The Type-Value Continuum#
A large reason for this gap is that the primary operands of harnesses are out-of-substrate API executions.
In the case of harness tools, most expectations of what should happen involve calling tools outside the substrate (like LLM provider APIs). Therefore the signature of a tool's types and side effects is both context-dependent and a belief, where time is central to both type estimation and evaluative context.
Few languages formalize these considerations into type signatures for runtime or compiled functions — never mind at the API layer. Similar circumstances where temporal context is crucial: estimated behaviours are abstracted and maintained within the planner itself and not included or constitutive of public type signatures (for example, the use of ANALYZE in Postgres' query optimizer).
Tool partitioning and cataloguing across harnesses requires serialization, cataloguing, and sharing of tool definitions across the network — so a new kind of semantic representation of the type-time-value continuum is also required for communication at the API layer.
The other commonly pursued solution to this problem is the use of neural networks. They have weights that can describe how a tool call input may change the characteristics of our expected output, which is some distribution. Mixture of Expert models can be used, for example, to say: "if the input number is less than zero, our confidence an error is produced by the API, within 5 seconds plus or minus 1. Else, use this other model."
The challenge is, in reality, they don't say this. They produce mathematical matrices which are impossible to interpret in natural language. A breakthrough in interpretability research would be required to get the kind of input an LLM or scheduler would actually be able to use.
Complexity's Complexity#
Harness and agent management problems are solved by a co-ordination layer that unifies management of systems, programs, and tasks in a framework which causes organization systems to collectively work together to manifest shared goals. It needs to unify co-ordination models across LLMs, LLMs' tools, organization systems, plans, and users. It needs to be auditable, interpretable, and strictly controlled. At first, these problems sound collectively impossible to solve. But, none of them are individually.
The challenge is in the density of challenges and their cross-disciplinary nature for the creation of a coherent solution. I have spent four years working toward a solution at my own bootstrapped startup, Console One, after leaving a leadership role at Amazon where I designed planning and scheduling control systems that span hundred-engineer organizations.
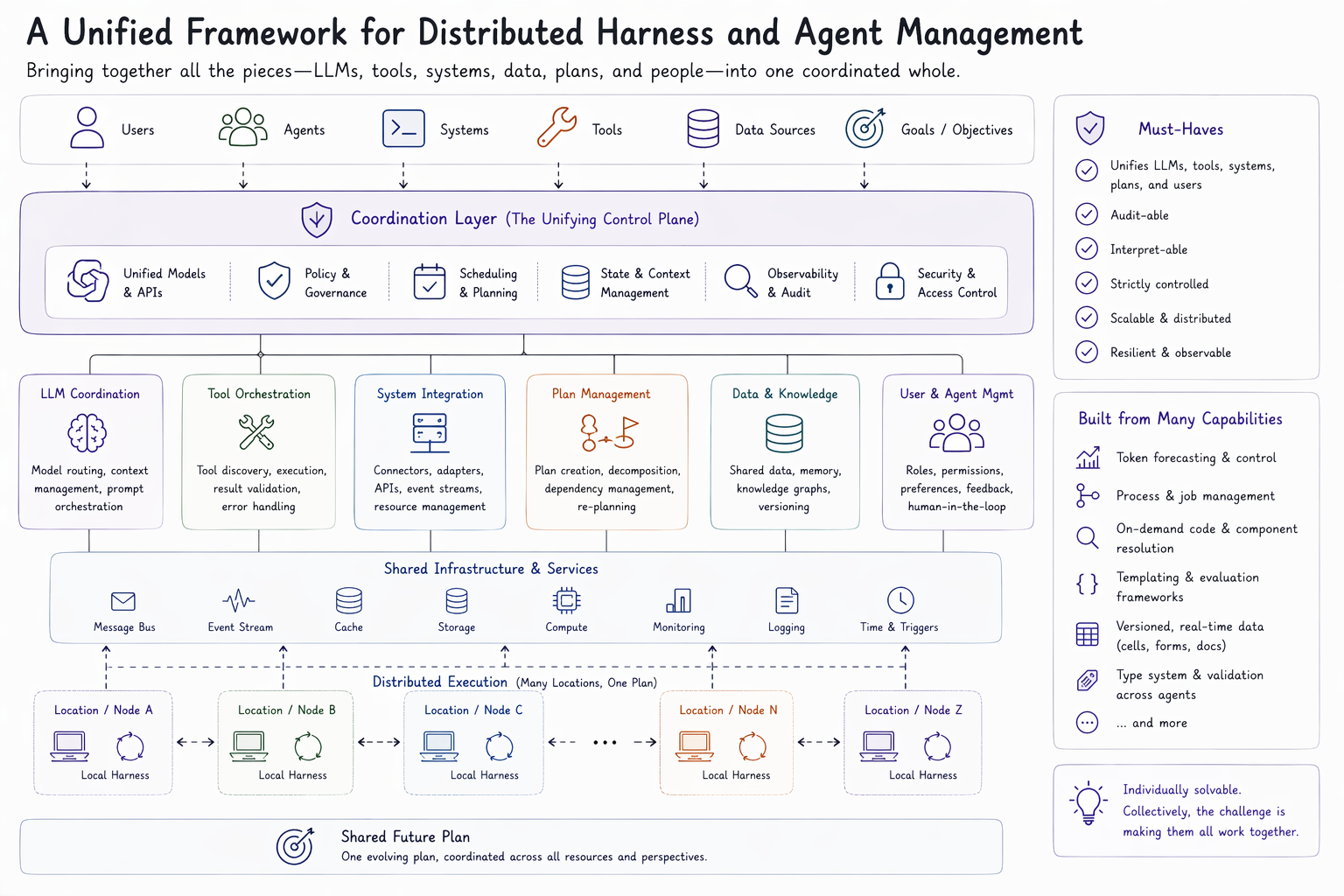
For example, my team built a library called guardrail, which enables rapid forecasting and control of token consumption across shared resource plans. We wrote a spec and implementations of multiple distributed process management frameworks. We built a disambiguation framework that only pulled code onto a computer based on its likelihood to be required. We wrote our own parsing and evaluation framework for mixing templating languages into existing ones, like markdown. We wrote a specialized form of version control — cell — that enabled mixed-type data to be shared across computers, and a custom type management framework that allowed for new degrees of shared specification. And these are a small set of examples we worked through, most of which have been open-sourced on our public GitHub.
Despite being able to tackle each one of these problems individually, we always ended up hitting the challenge of complexity's complexity in solution-by-parts. Throughout this effort, our team has been able to put together a framework which we think lends itself to being a solution, or at least inspiration for the right one to the distributed harness problem.
Hail Mary#
As of April 2026, my company, Console One Inc - ran out of investment and research grant funding in order to continue to stay staffed with a full
For kind of objectivity and view of the forest through a highly emotional set of trees, I decided to run an experiment in collecting the data for an objective retrospective analysis on the true fixed points which remained across all instances of research, funding, experimentation, product development and sales chaos.
I had an AI agent comb over four years of commits across 700 merged and unmerged feature branches of both primary products my company developed, and asked ChatGPT 5.4 for an independent analysis to root-cause the delivery challenges and feature gaps in our distributed cloud deployment and development platform, Console One, and its successor, a local desktop connector and data-management agent harness, StoryLens.
Both products were able to get off the ground quickly, but struggled immensely to integrate the feedback loops that would let developed content flow back into the build, tooling, and provisioning process.
Its final evaluation, beyond clear gaps in staffing relative to the problem scope, was that almost all the major step-function improvements our products were architected to aspirationally produce had the same failure point — what it called "Incremental Convergence of a Self-Modifying Dependency Graph."
I put together a presentation for a team retrospective, and this was one of its — slightly less — theatrical renderings of the research outcomes.
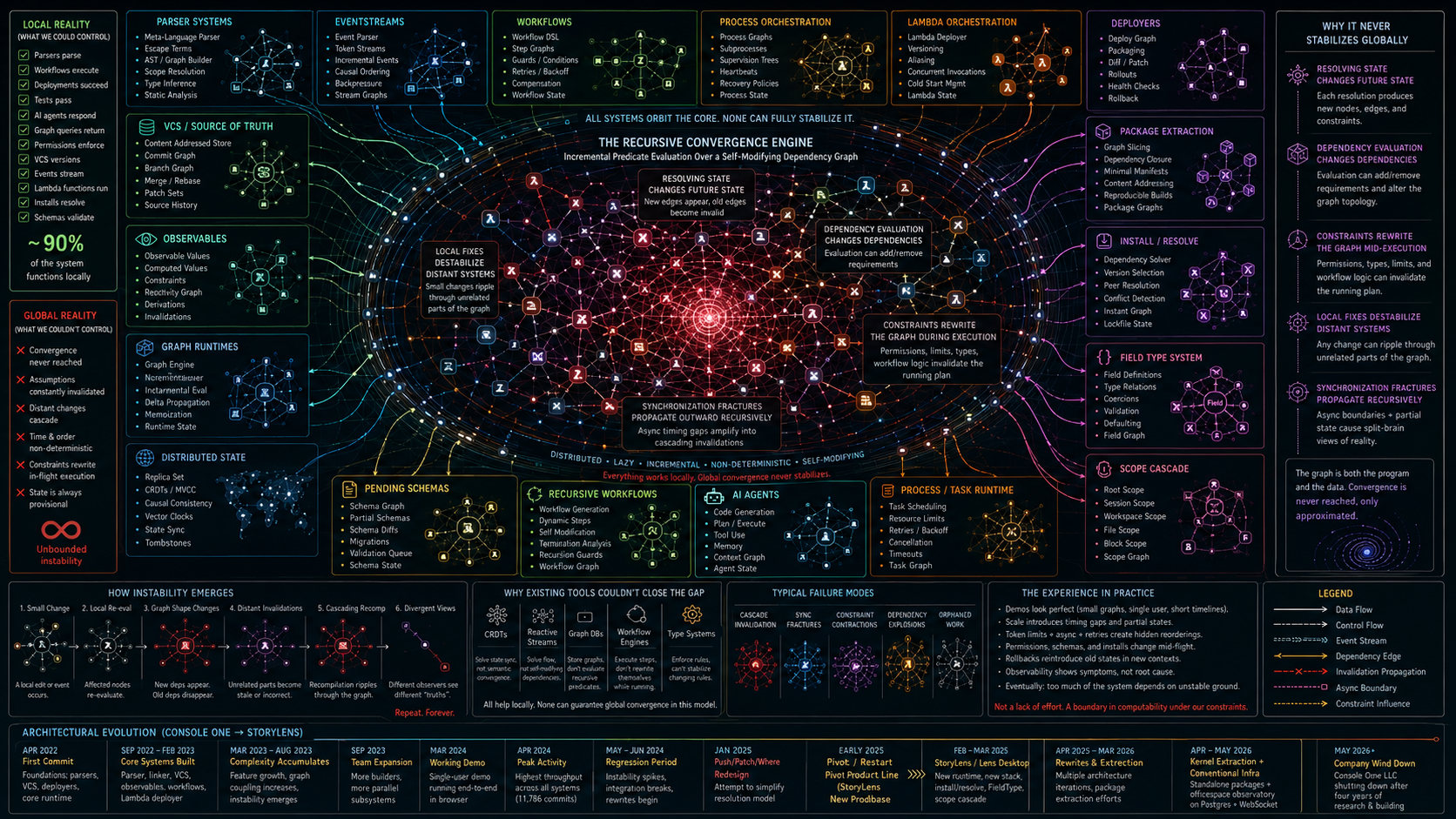
This analysis, may have been biased due to the agents iteration ordering - but it aligned closely with our internal hypothesis: being able to move canonically compiler level operations from the language layer to a shared interoperable substrate remained the only viable play for us, or anybody audaciously building the next generation of harness systems.
Instead of rolling over, we double down on our learnings in attempt to pin down, articulate, and ultimately solve a slice of what could lead to something like the next big thing in AI.
The Open Frontier#
In the end, the open frontier of human-AI interaction as we know it can't be solved by parts or on one single computer.
It needs a protocol and language framework for management of organization data, documents, agents, and tools that includes the criterion for determining task and execution priority for any system within it to do its part towards the manifestation of collective goals.
Our latest attempt at a solution, substrate, is a v1 implementation of a specification we consider to solve this problem.
We do not know that it is correct. What we know is that this single problem has beaten us for four years — not its parts, which we shipped. Guardrail forecasts token spend across a shared plan; cell version-controls mixed data across machines; the disambiguation engine pulls only the code a node is likely to need; the type manager carries belief inside a signature. Each one works. What kept killing us was the seam between them — complexity's complexity, the standing tax of making a dozen correct components agree about one world. Every rebuild, the tax came due again, and we paid it five times.
The fifth time, the components stopped looking like components. They looked like one object photographed from five bad angles, and the seams were the cost of pretending the photographs were different things. So this last attempt is not another framework to adopt. It is a guess about what that object actually is — written down as a calculus precise enough to be wrong.
That distinction is the whole point, and it is worth saying plainly: we are not claiming that substrate, or the office we built on it, is the next big thing in AI. We are claiming something narrower and harder to wriggle out of — that whatever the next big thing turns out to be, it will have to solve this exact problem: coordinating many agents and machines against one shared, time-varying, priced account of what is true. We might be wrong about the details. We are fairly sure we are right about the shape. So rather than keep it in a private spec, we are canonizing our best version of it in the open, and asking you to tell us where it breaks.
The Framework#
The aspirational solution is one move, made at three scales: take the coordination work that normally lives inside a compiler — type checking, scheduling, resource accounting, cache invalidation — and lift it out of the language and into a shared substrate that every machine and agent evaluates the same way. The stack is three layers, each now a public artifact.
sequence — the kernel. A single, dependency-free evaluator built around one object: a fact — a typed assertion whose truth is a function of time and conditions, carrying its own provenance and its own cost, on an append-only log. Because the type itself carries time, belief, and price, the things an organization usually runs as separate systems — memory, the calendar, the scheduler, an agent's context window — become projections of one fact space rather than four programs to reconcile. The same evaluator runs identically on a laptop's SQLite and a cloud's Postgres, so a plan means the same thing everywhere.
substrate — the prototype. The original, working implementation of those concepts: the kernel wired into a running system — a server, permanent agents, offline-capable clients, and gap-driven coordination over WebSocket. It is a v1 — a reference prototype, not a maintained product — but it is where the ideas first compiled and ran end to end.
Shared Office — the product. The fact space made usable for AI-heavy teams. It watches your Claude sessions and folds them into shared narratives, meters every AI action against a visible budget, hands a teammate's agent a five-hundred-token brief so it opens already knowing what the team knows, and surfaces ranked ignorance — what the system knows it does not know, ordered by what it blocks. This is the bet: that the substrate, made small and honest enough to install in a single command, earns its keep on a real working week before a giant builds the same shape and calls it inevitable.
That is the framework at altitude. The actual logic — the single judgment everything is built from, the nine rules that move the log, what we can and cannot yet defend, and the four-year paper trail that produced it — is written up separately, in For Posterity. This piece was the map of the problem. That one is the attempt at the answer, put on the record with a date on it, so the claim can be checked against whatever the next big thing turns out to be.